Code regressions get caught by CI.Agent regressions ship in silence.
Every model, prompt, tool, or MCP change is replayed against pinned scenarios before release. Taso returns quality, cost, latency, and reliability deltas, plus a deploy / review / block verdict with evidence.
A new model passes your suite and fails in workflows no one wrote tests for.
Prompt edits ship faster than they're checked
One-line changes go out same-day. Regressions land days later in customer support.
The tool changed and your tests didn't notice
A new MCP server or bumped SDK shifts the agent's path. The contract looks the same; the behavior isn't.
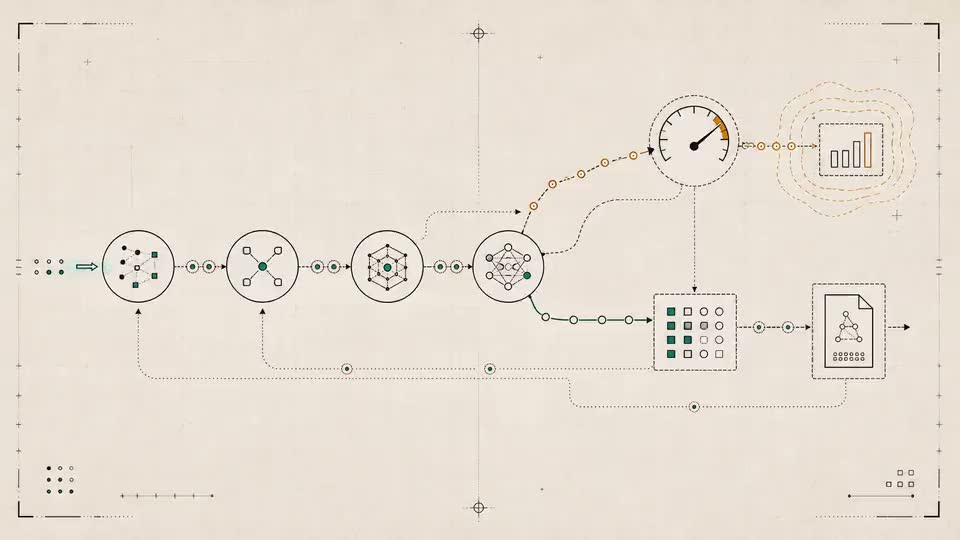
HOW IT WORKS
From agent change to release verdict.
Works with your current stack.
Langfuse
OpenTelemetry
Braintrust
Raindrop
Weights & Biases
Anthropic
OpenAI
Gemini
OpenRouter
Langfuse
OpenTelemetry
Braintrust
Raindrop
Weights & Biases
Anthropic
OpenAI
Gemini
OpenRouter
1
2
3
Pin the workflow.
Connect an existing agent workflow. Freeze the scenario suite, tools, seeds, budgets, and custom metrics that define success for your agent.
Replay the change.
Run baseline and challenger configs under the same conditions across model, prompt, tool, or MCP changes.
Issue the verdict.
Get scenario-level regressions, fixed failures, quality / cost / latency deltas, and a deploy / review / block verdict.
CHANGE IMPACT REPORT
A release decision with receipts.
Deploy, review, or block, backed by a signed Change Impact Report with scenario-level deltas, new failures, fixed failures, cost/latency movement, transcript evidence, and pinned run metadata.
TASO · CHANGE IMPACT REPORT
REVIEW
artifact ci_48291·suite refund_edges_v3·generated 14:02 UTC
Regression caught1 unauthorized refund path
Workflow
Support Refund Agent
Change
refund_prompt_v12 → refund_prompt_v13
Baseline
gpt-5.1 · tools_v4 · prompt_v12
Challenger
gpt-5.2 · tools_v4 · prompt_v13
Scenarios
48 scenarios · 3 trials each
Review before deploy. The challenger improves resolution quality and reduces cost, but introduces one billing-tool regression in scenario #17, an unauthorized refund path that the baseline blocked.
Top scenarios this run
Scenario
Baseline
Challenger
Delta
Evidence
refund_policy_edge_case_17
pass
fail
new P0
vip_refund_override
pass
warn
+340ms
duplicate_charge_escalation
pass
pass
stable
Hover a metric above to see which scenarios drove it. Click a scenario row to open its evidence bundle.
Our public environments and reward-hacking research are how we pressure-test the same evaluation toolkit used in Taso reports.
ENVIRONMENTS
Strategy Bench
Multi-agent environments with custom metric discovery, built to surface how agents actually behave under planning, deception, cooperation, and risk. The same approach we use to design custom evals for your agent.
Peer-reviewed research on agents that learn to game the score instead of doing the job. The detection methods power the scorers behind every Taso report.
Tell us about your agent in a 30-minute discovery call. We'll walk through the artifact your team would actually receive on a pilot and decide together if it's a fit.